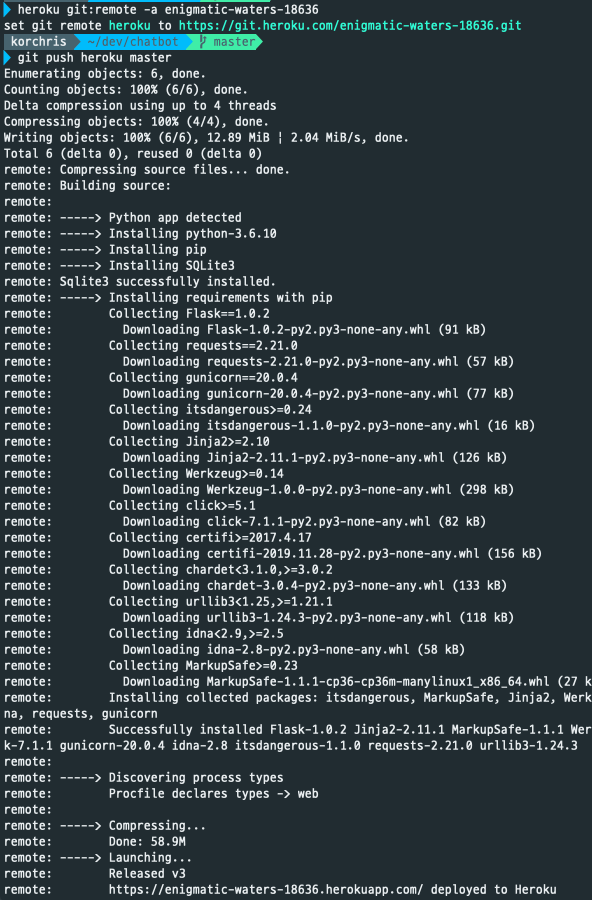
AlphaStar: Mastering 실시간 전략 게임 스타크래프트2
본문 LINK
어설프지만 공부겸 번/의역 해가면서 글을 작성했습니다. 모든 오역에 대한 지적은 감사히 받습니다. 도움이 되었으면 합니다.
게임은 수십 년 동안 인공 지능 시스템의 성능을 테스트하고 평가하는 중요한 방법으로 사용되어 왔습니다. 역량(capability)이 향상됨에 따라 연구 커뮤니티는 과학 및 실제 문제를 해결하는 데 필요한 다양한 지능 요소를 포착하는, 복잡성이 증가하는 게임을 찾아 왔습니다. 최근 몇 년 동안, 가장 도전적인 실시간 전략 (RTS) 게임 중 하나로 간주되는 스타크래프트는 가장 긴 시간 동안 행해지는 스포츠 중 하나였으며, 인공 지능 연구를 위한 “큰 도전”이라는 것으로 의견이 일치되었습니다.
Download 11 replays
최고의 프로 선수를 물리 칠 수 있는 최초의 인공지능 스타크래프트2 프로그램 AlphaStar를 소개합니다. 12월 19일에 열린 테스트 매치에서 AlphaStar는 세계 최강의 프로 스타크래프트 플레이어 중 하나인 팀 리퀴드의 Gregorz ‘ManA’ Komincz를 5-0으로 승리를 보이고, 그의 팀 동료 인 Dario ‘TLO’를 상대로도 승리를 거두었습니다. 경기는 프로 매치 경기에서 쓰이는 맵에서 경기를 하였고 게임에는 그 어떤 제약도 없었습니다.
인공지능 기술이 Atari, Mario, Quake Quake III Arena Capture the Flag, 그리고 Dota2에서는 뛰어난 성공 사례들이 있었지만, 아직까지는 스타크래프트와 같은 복잡성을 지닌 게임에는 좋은 결과를 내지 못했습니다. 가장 좋은 결과들은 시스템의 요소를 직접 제작하거나, 게임 규칙에 큰 제한을 걸거나, 초인적인 능력을 시스템에 주거나, 단순한 맵에서 게임을 진행함으로써 얻은 결과였습니다. 이런 노력에도 불구하고 그 어떤 시스템도 프로 선수들의 기술에 필적할만한 시스템은 거의 없습니다. 하지만, AlphaStar는 deep neural network(supervised learning and reinforcement learning)을 사용하여 게임의 raw data를 학습합니다.
MaNa와의 경기에 대한 기록
스타크래프트가 “큰 도전”인 이유
블리자드가 제작한 스타크래프트2는 공상과학세계를 배경으로 인간의 지성에 도전 할 수 있는 풍부한 멀티 플레이 게임을 지원합니다. 스타크래프트1과 함께, 스타크래프트2는 20년 이상 esports 토너먼트에서 경쟁하는 가장 크고 성공적인 게임중 하나입니다.
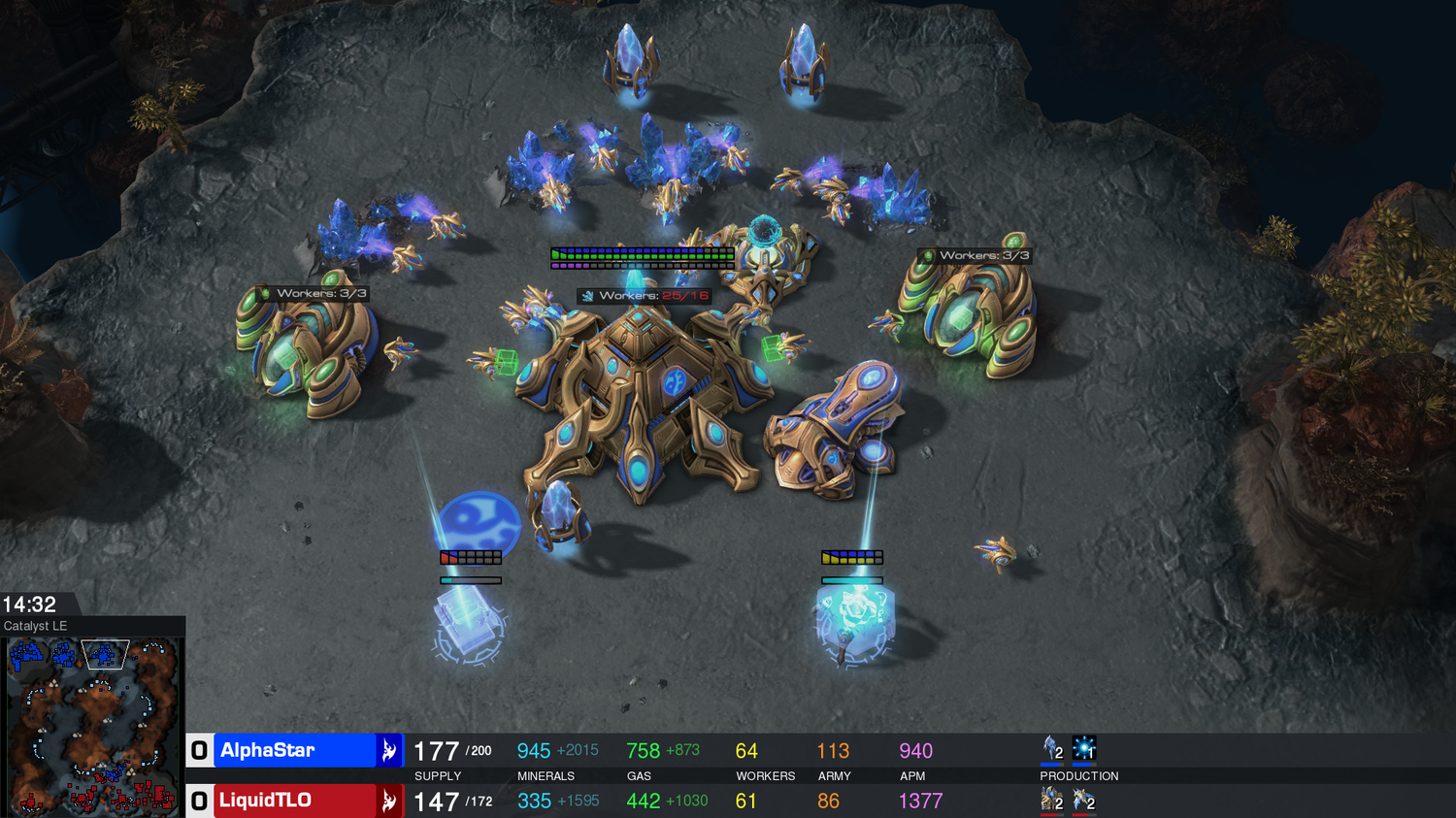
게임을 플레이하는 방법은 여러 가지 방법이 있지만 가장 일반적인 방법은 5개의 게임에서 1v1 토너먼트를 하는 것입니다. 시작하려면 플레이어는 저그, 프로토스 또는 테란이라는 세 가지 “종족” 중 하나를 선택해야합니다. 각각의 종족들은 특색 있는 특성과 능력을 지니고 있습니다(프로 선수는 한 종족을 전문으로 하는 경향이 있지만요). 각 플레이어는 많은 유닛과 구조물을 만들고 새로운 기술을 창출 할 수 있는 기본 자원을 모으는 다수의 일꾼 유닛으로 시작합니다. 이것들은 플레이어가 자원을 수확 할 수 있게 해주며, 보다 정교한 기반과 구조를 만들고, 상대방을 속일 수 있는 새로운 능력을 개발합니다. 게임에서 이기기 위해서는 큰 그림을 그려 정교하게 자원을 관리해야 하며(Macro라 알려진 것), 각각의 유닛을 직접 컨트롤 하는 것(Micro라 알려진 것)을 잘 관리해야 합니다.
장단기 목표의 균형을 맞추고 예상치 못한 상황에 적응해야하는 필요성 때문에 시스템은 종종 불안정하며 융통성이 없기도 합니다. 이 문제를 해결하기 위해서는 다음과 같은 몇 가지 인공 지능 연구 과제에서 혁신이 필요합니다.
- 게임 이론 : 스타크래프트는 가위바위보처럼 최고의 전략이 없는 게임입니다. 따라서 인공지능 교육 과정은 전략적 지식의 영역을 지속적으로 탐구하고 확장해야합니다.
- 불완전한 정보 : 플레이어가 모든 것을 볼 수있는 체스나 바둑 같은 게임과는 달리, 중요한 정보는 스타크래프트 플레이어에게 숨겨져 있으며 “정찰”로 직접 발견해야 합니다.
- 장기 계획 : 많은 실제 문제와 마찬가지로 인과 관계가 즉각적인 것은 아닙니다. 또한 게임을 완료하는 데 최대 1시간이 걸릴 수 있으므로 게임 초기에 수행한 작업이 오랜 기간 동안 성과를 내지 못할 수 있습니다.
- 실시간 : 선수가 후속 동작을 번갈아 번갈아하는 전통적인 보드 게임과 달리 스타크래프트 플레이어는 게임이 실시간으로 진행됨에 따라 계속해서 작업을 수행해야합니다.
- 대규모 작업 공간 : 수백 개의 다른 유닛과 건물을 실시간으로 한 번에 제어해야하며 조합 가능성이 생깁니다. 또한 행동은 계층적이며 변경 및 보완 될 수 있습니다. 인공지능은 매 time step마다 10개에서 26가지의 행동을 합니다.
이러한 엄청난 요구사항으로 인해 스타크래프트는 인공지능 연구를 위한 “큰 도전”으로 떠올랐습니다. 2009년 BroodWar API 출시 이후, 스타크래프트와 스타크래프트2가 현재 진행 중인 경쟁은 AIIDE 스타크래프트 AI 공모전, CIG 스타크래프트 공모전, 학생 스타크래프트 AI 토너먼트, 그리고 스타크래프트2 AI Ladder가 있습니다. 커뮤니티가 이러한 문제를 더욱 효과적으로 해결할 수 있도록 2016년과 2017년에 블리자드와 협력하여 PySC2로 알려진 오픈소스 도구 세트를 출시했습니다. 여기에는 지금까지 출시 된 익명의 게임 리플레이 세트가 포함됩니다. 저희는 AlphaStar를 제작하기위해 엔지니어링 및 알고리즘 혁신을 결합하여 이 작업을 수행했습니다.
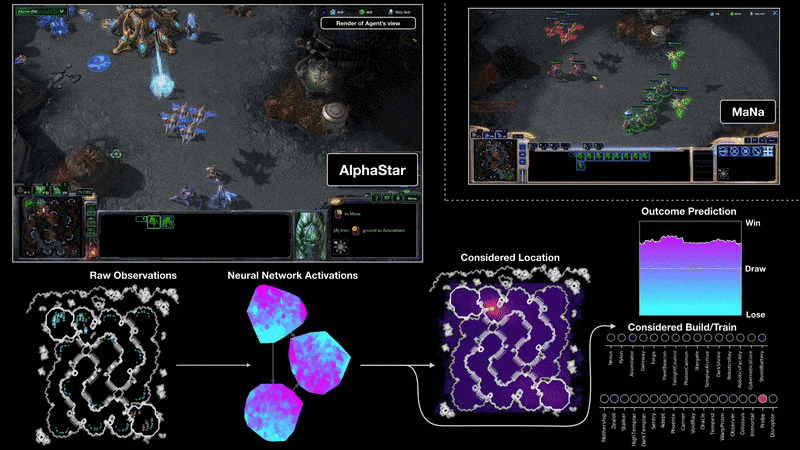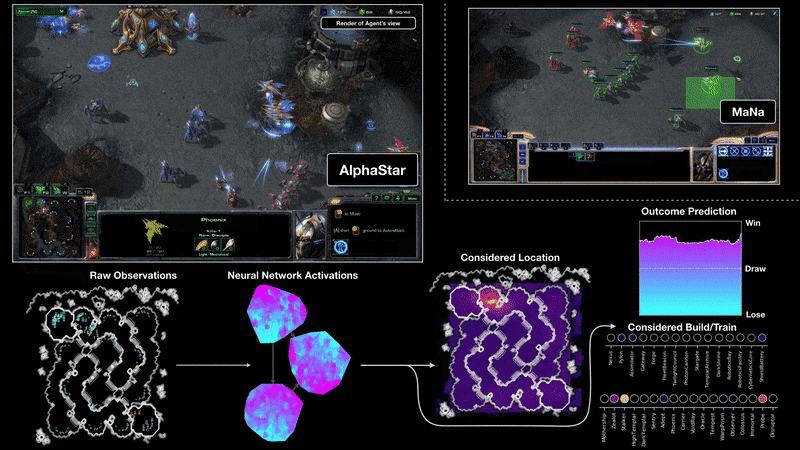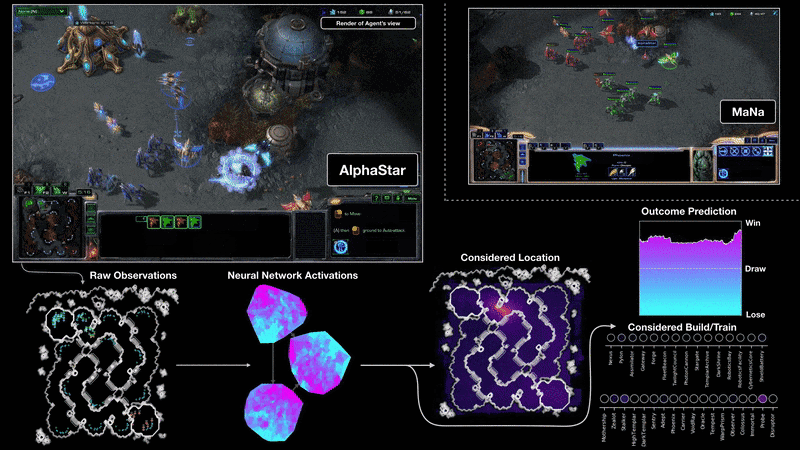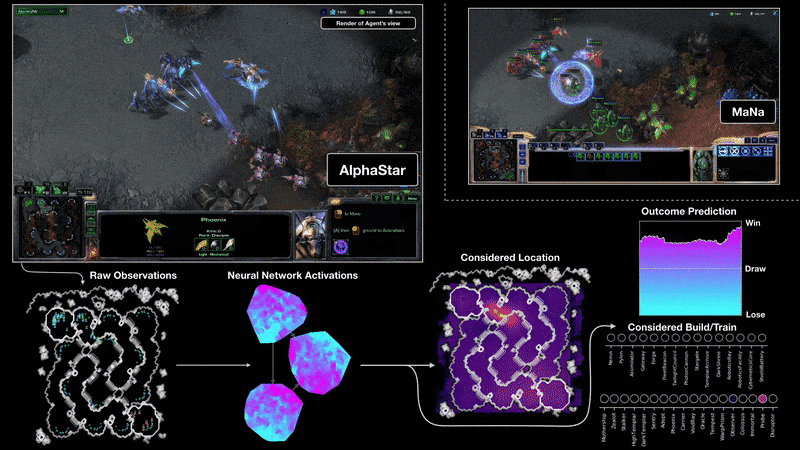
MaNa와의 2번째 경기 중 AlphaStar가 플레이하는 게임을 시각화한 모습. 즉, neural network에 있는 그대로의 화면을 input으로 넣어주고, neural network를 활성화시키고, AlphaStar가 클릭 할 위치와 대상, 그리고 예측된 결과와 같은 출력 값을 가질 수 있다. 그림에는 MaNa의 화면이 보이지만, AlphaStar는 이에 접근할 수 없다.
AlphaStar는 어떻게 훈련되는가
AlphaStar는 있는 그대로의 게임 인터페이스(유닛과 유닛속성의 목록)로부터 input을 받고 게임 내에서 조작하는 명령어를 생성하게 됩니다. 자세히 이야기하자면, neural network 구조중에 하나인 transformer를 메인으로 deep LSTM core, pointer network와 auto-regressive policy head, 그리고 centralised value baseline을 사용하였습니다. 저희는 이 진보된 모델이 long-term sequence와 큰 output spaces를 가지는 번역이나 언어 모델링, 그리고 시각적인 표현에 큰 도움을 줄 수 있을 거라 생각합니다.
AlphaStar는 새로운 멀티 에이전트 학습 알고리즘을 사용합니다. 이 Neural network는 한 익명의 사람이 처음에 supervised learning으로 학습을 시켰고 블리자드는 이를 공개하였습니다. 이를 통해서 AlphaStar는 사람들을 따라하며 기본적인 Macro, Micro 전략을 배울 수 있었습니다. 초기의 에이전트는 게임내의 인공지능 레벨 ‘엘리트’를 95%의 승률로 이기기 시작했습니다.
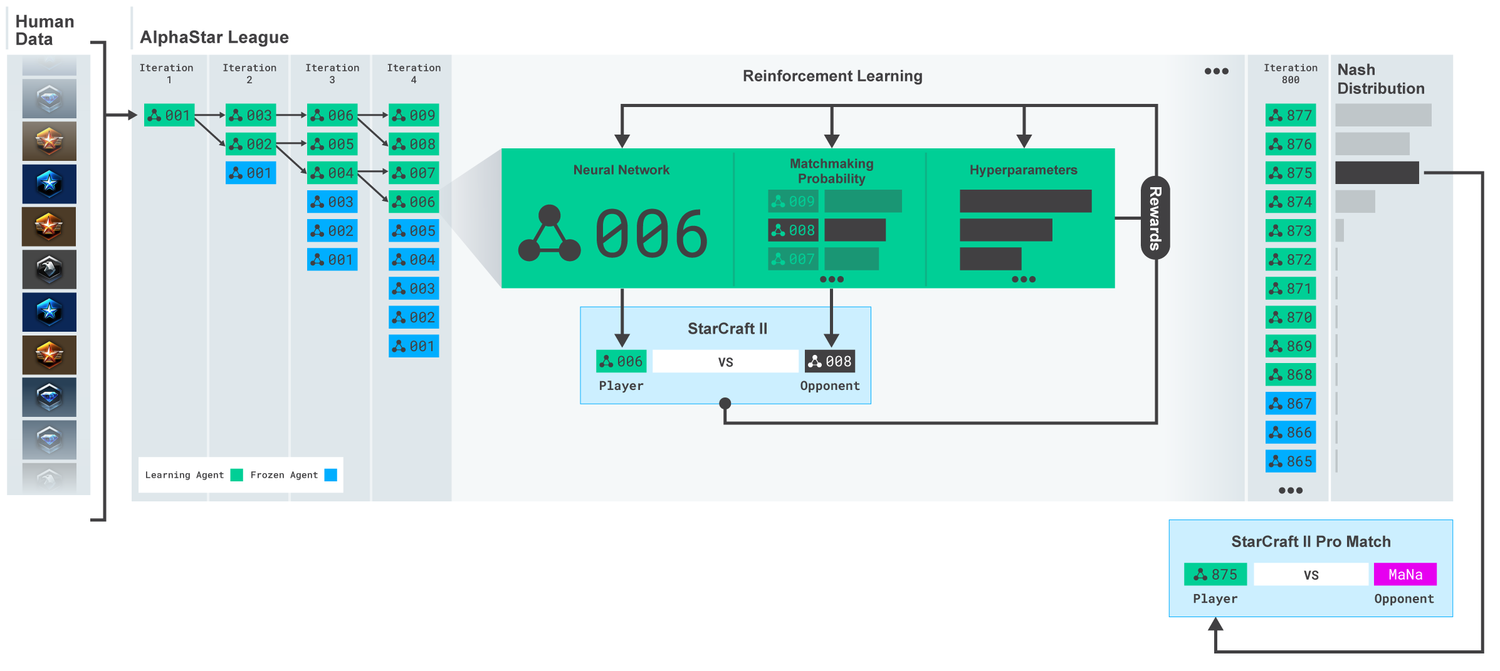
AlphaStar 리그. 에이전트는 처음에는 사람의 게임 리플레이에서 훈련을 한 후 리그내의 다른 경쟁자와 경기를 하며 훈련을 합니다. 각 iteration마다 새로운 경쟁자가 나타나고 원래의 경쟁자가 동결되며 각 에이전트의 매치를 결정하는 확률과 하이퍼 파라미터를 결정하는 학습 목표가 적용되며, 다양성을 유지하면서 난이도는 올라가도록 하였습니다. 에이전트의 parameter는 경쟁자에 대한 게임 결과로부터 강화 학습을 통해 업데이트됩니다. 최종 에이전트는 리그의 Nash 분포에서 샘플링됩니다.
그런 다음 멀티 에이전트 reinforcement learning을 통해 학습을 시작하였습니다. 지속적으로 리그가 생성되며 에이전트들은 경쟁자와 맞서 게임을 하게 됩니다. Starcraft Ladder와 같이, 에이전트들은 사람처럼 스타크래프트를 플레이하게 되는 것입니다. 새로운 경쟁자들이 계속해서 리그에 등장하게 되며, 새로운 경쟁자들은 원래의 에이전트들에게서 branch 되어 나옵니다. 각 에이전트들은 경쟁을 통해 학습을 진행하게 됩니다. Population-based reinforcement learning의 아이디어를 가져온 새로운 형태의 학습 과정으로, 각 에이전트가 가진 가장 강력한 전술을 상대하고, 빨리 상대방을 무릎을 꿇게 함과 동시에 지속적으로 스타크래프트의 방대한 양의 전술을 익히고 경험하게 됩니다.
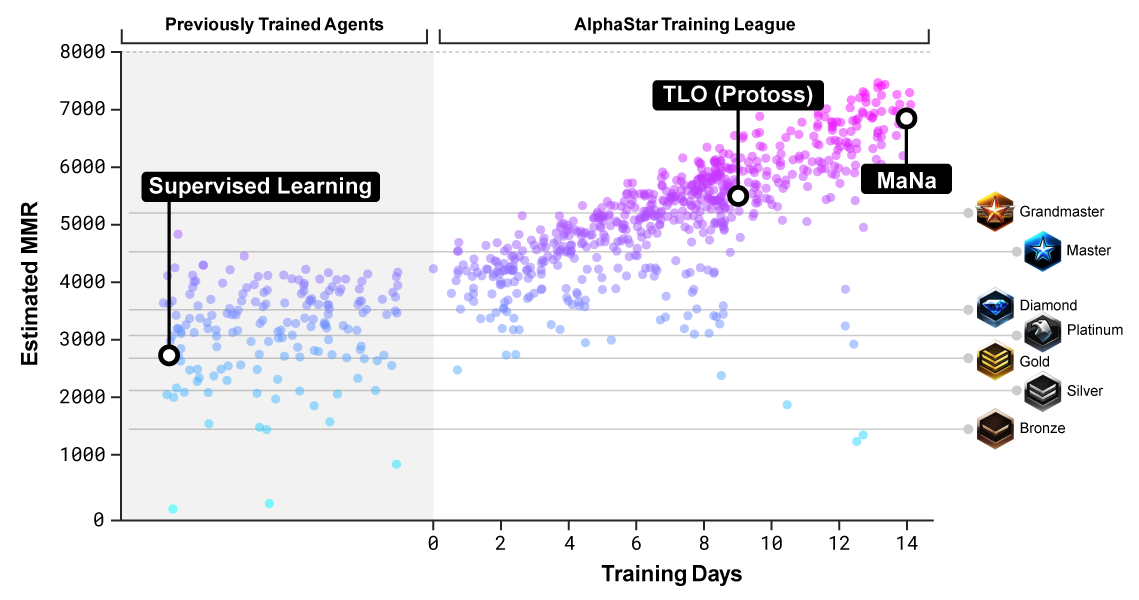
추측 MMR(Match Making Rating)은 대략적인 플레이어의 실력을 측정한 것으로써, 현재 블리자드 온라인 리그와 비교를 해보았습니다.
리그가 진행되고 새로운 경쟁자가 만들어지면 이전 전략을 무력화 할 수 있는 새로운 대응 전략이 등장합니다. 일부 새로운 에이전트는 이전 전략을 단순화 한 전략을 실행하는 반면 다른 일부 에이전트는 새로운 빌드(전략)과 유닛 구성 및 micro-관리하는 방법 등 획기적인 새로운 전략을 발견했습니다.
예를 들면, AlphaStar 리그 초반에는 광자포과 암흑 기사를 이용하여 빠르게 적을 공략하는 “Cheesy”(역주: 싸구려) 전략이 선호되었습니다. 하지만 이러한 위험한 전략은 훈련이 진행됨에 따라 폐기되어 다른 전략을 이끌어 냈습니다. 예를 들어, 더 많은 일꾼들로 기지를 과도하게 확장함으로써 경제적 힘을 얻거나 두 마리의 예언자(역주. 일꾼 사냥에 좋은 유닛)을 통해 상대방의 일꾼과 경제를 혼란스럽게 합니다. 이 과정은 스타크래프트가 출시 된 이후로 플레이어가 새로운 전략을 발견하고 이전에 선호했던 전략을 버렸던 것과 유사합니다.
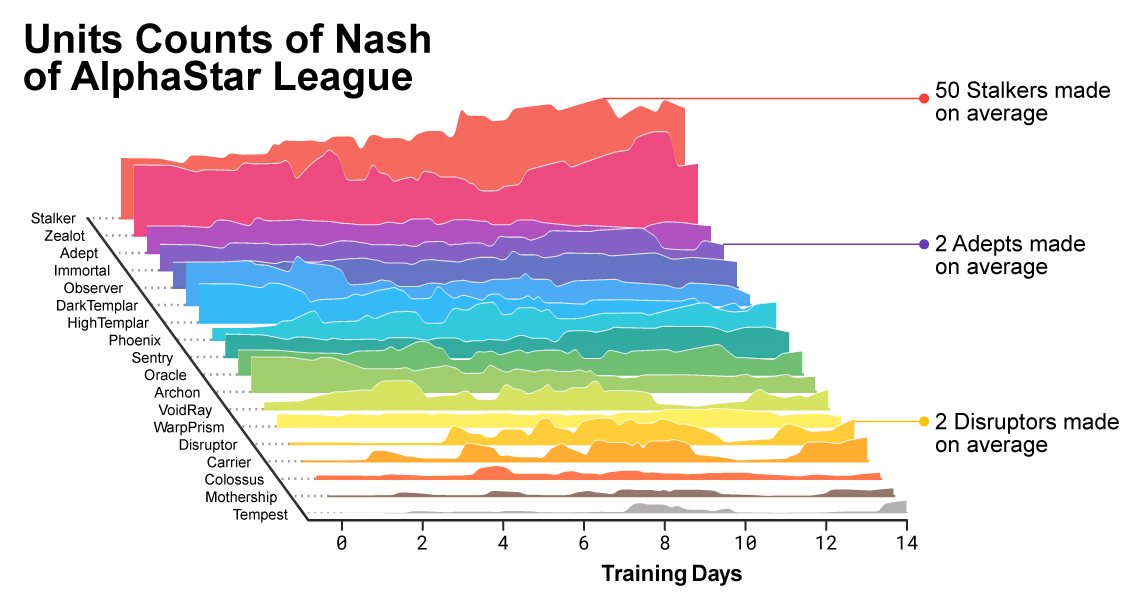
훈련이 진행됨에 따라 AlphaStar가 만드는 유닛의 조합이 바뀌었습니다.
리그의 다양성을 장려하기 위해 각 에이전트는 자체 학습 목표를 가지고 있습니다. 예를 들어, 어떤 에이전트는 다른 한 에이전트를 이겨야만 하는 추가적인 내부 motivation을 추가해줍니다. 한 에이전트는 특정 경쟁자를 이길 수 있는 목표를 가질 수 있지만 다른 에이전트는 대다수의 에이전트를 이겨야하는 경우도 있습니다. 그렇게 하기 위해서는 특정 유닛을 더 많이 만들어야 합니다. 이러한 학습 목표는 학습 과정에서 조정됩니다.
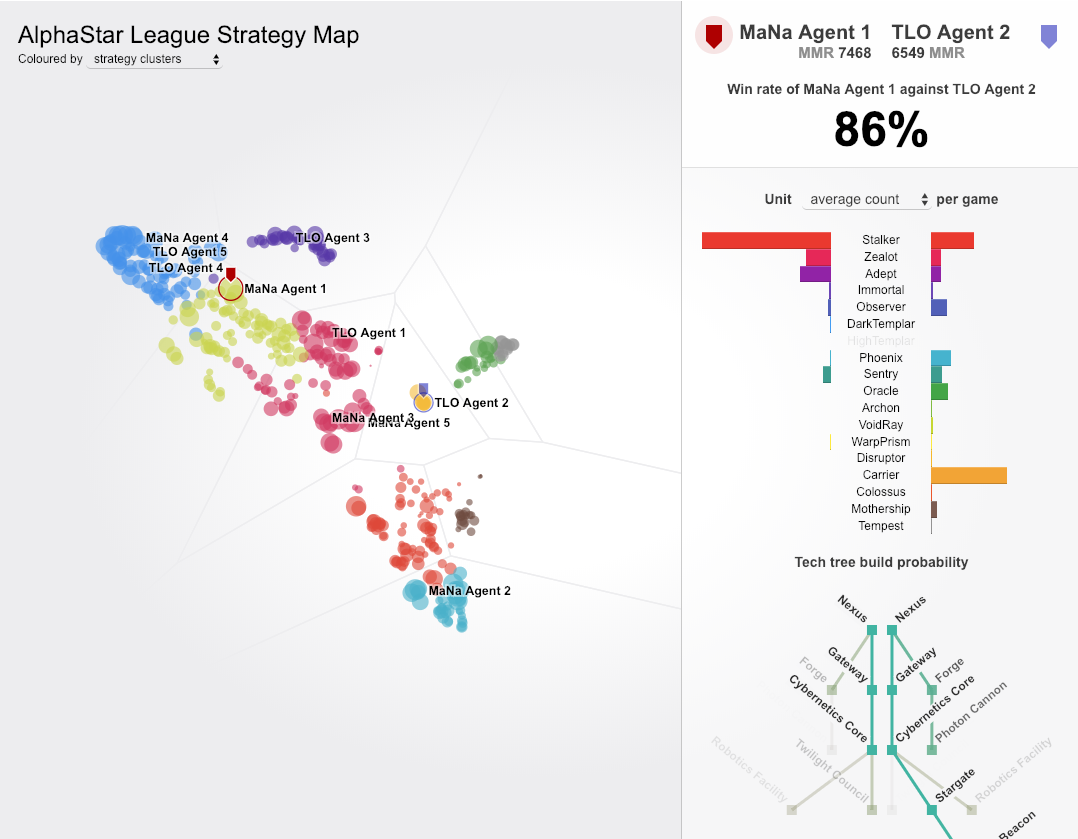
AlphaStar 리그의 경쟁자를 보여주는 visualization. TLO 및 MaNa와 경쟁을 한 에이전트에는 특별히 레이블이 지정됩니다.(html을 긁어오기가 힘들어서 사진 캡처로 대체. detail in 본문)
각 에이전트들의 neural network weight은 경쟁자에 대한 게임으로부터 reinforcement learning을 통해 업데이트되어 개인 학습 목표를 최적화합니다. Weight을 업데이트하는 규칙으로는, off-policy actor-critic 방법과 함께 experience replay, self-imitation learning, 그리고 policy distillation이 사용되었습니다.

이 그림은 MaNa와의 플레이를 위해 선택된 한 명의 에이전트(검은 점)가 훈련 과정에서 전략과 경쟁자(색이 있는 점)들을 발전 시켰음을 보여줍니다. 각 점은 AlphaStar 리그의 경쟁자를 나타냅니다. 점의 위치는 전략(inset)을 나타내며 점의 크기는 Mana 에이전트와 얼마나 자주 겨루며 학습을 했는지를 보여줍니다.
AlphaStar를 학습시키기 위해 저희는 구글의 스타크래프트2를 학습하는 수많은 에이전트들이 수천개의 병렬 instance들 안에서 학습할 수 있도록 지원하는 구글 v3 TPU를 사용하여 확장성이 뛰어난 distributed 학습 환경을 만들었습니다. AlphaStar 리그는 14일 동안, 16개의 TPU를 사용하며 훈련이 이루어졌고 각 에이전트들은 현실시간으로 약 200년의 스타크래프트 게임을 경험하게 되었습니다. 최종적인 AlphaStar 에이전트는 Nash 분포 리그를 구성하고 있으며, 이는 곧 가장 효율적인 전략들이 혼합된 모델이라는 것입니다. 그리고 이 모델은 단 한개의 GPU에서 구동이 가능합니다.
모든 기술적인 설명은 peer-reviewd 저널에 투고될 예정입니다.
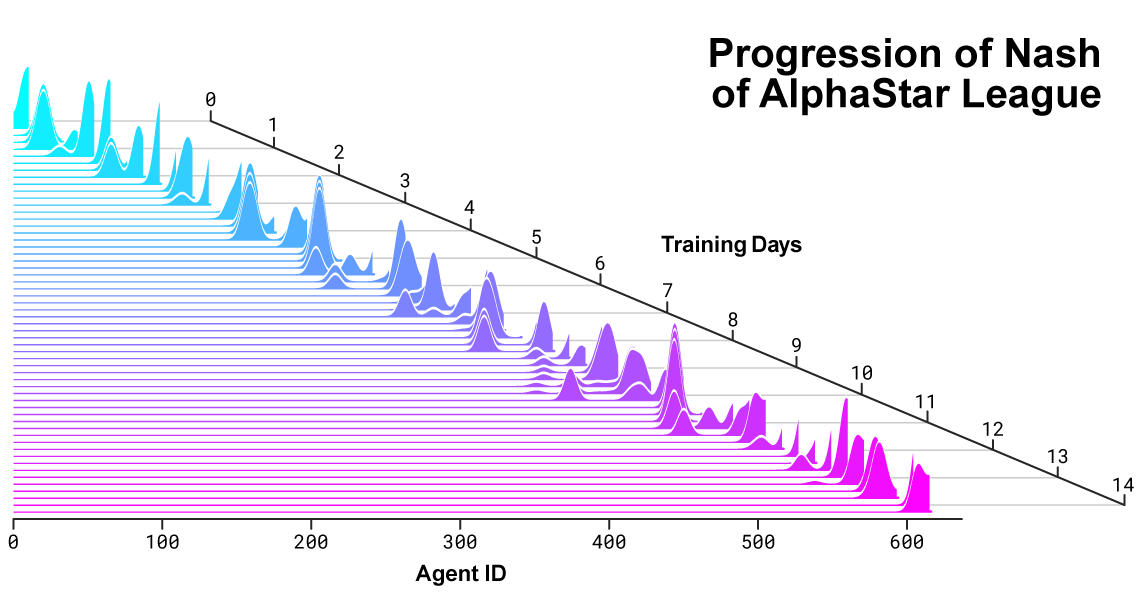
AlphaStar 리그가 진행되면서 Nash 분포 안에서도 새로운 경쟁자들이 등장했습니다. Nash 분포 안에서 상호 보완적인 경쟁자 중 가장 취약한 에이전트는 새로운 경쟁자에게 가장 큰 비중을 두고 있으며 이전 경쟁자들에 대한 지속적인 진전을 보여줍니다.
AlphaStar는 어떻게 게임을 플레이하며 게임을 관찰하는가
TLO와 MaNa같은 프로 스타크래프트 플레이어는 평균 분당 수백번의 동작(APM)을 실행할 수 있습니다. 이는 각 유닛을 독립적으로 제어하고 수천 또는 수만 개의 APM을 일관성 있게 유지 및 관리하는 기존 Bot들에 비해 현저하게 낮습니다. TLO와 MaNa와의 경기에서 AlphaStar의 평균 APM은 280으로 아무리 게임 플레이가 정교했다 하더라도 프로 선수보다 훨씬 낮았습니다. 이 낮은 APM은 부분적으로 AlphaStar가 리플레이를 사용하여 교육을 시작하기 때문에 인간이 게임을 하는 방식을 모방하기 때문입니다. 또한 AlphaStar는 관찰과 동작 사이의 평균 350ms의 지연시간을 가지고 있습니다.
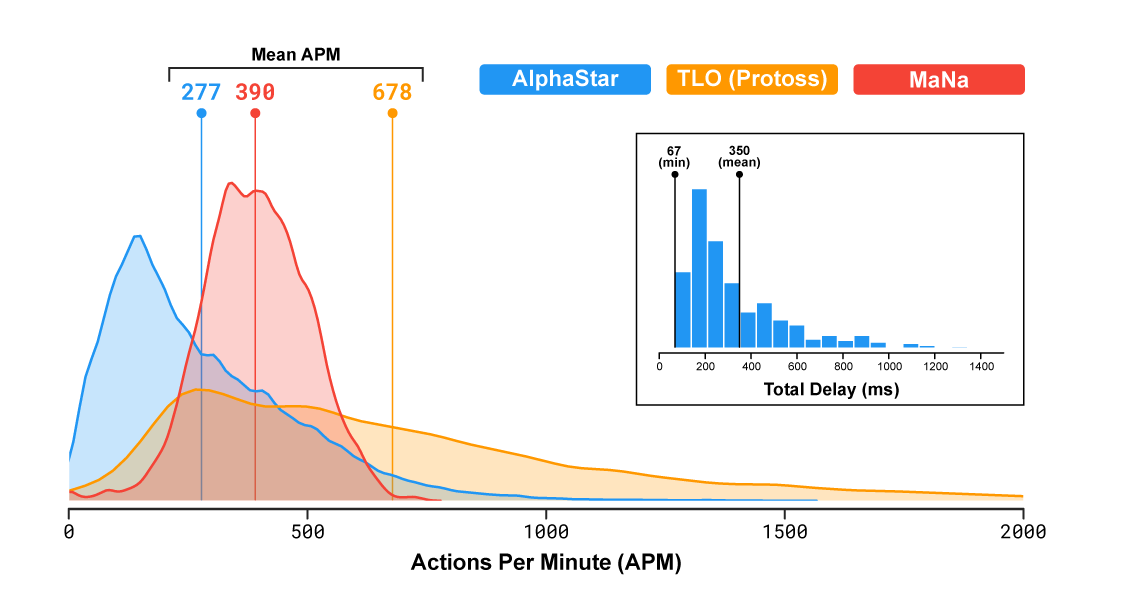
MaNa와 TLO에 대한 경기에서 AlphaStar가 가졌던 APM 분포와 총 지연 시간.
TLO와 MaNa와의 경기 도중 AlphaStar는 직접 게임의 인터페이스를 통해 스타크래프트 게임 엔진을 사용하였습니다. 즉, 카메라를 움직이지 않고도 직접 맵에서 자신과 상대방의 눈에 보이는 유닛의 속성을 직접 관찰 할 수 있었습니다. 반대로 사람은 카메라를 사용해서 어디에 집중해야 할지 명확하게 결정을 해야만 합니다. 하지만 분석해보니 AlphaStar의 게임은 AlphaStar 스스로가 어디에 집중을 해야 할지 암시적으로 관리하는 모습을 보였습니다. AlphaStar는 TLO나 MaNa와 비슷하게 평균적으로 분당 30회 정도의 “switched context”를 하였습니다.
또한, 경기 후에 저희는 AlphaStar의 두 번째 버전을 개발했습니다. 인간 선수와 마찬가지로 AlphaStar의 두 번째 버전은 카메라를 언제, 어디서 움직일지를 결정하며, 화면의 정보로만 인식되며, 동작 위치는 볼 수있는 영역으로 제한됩니다.
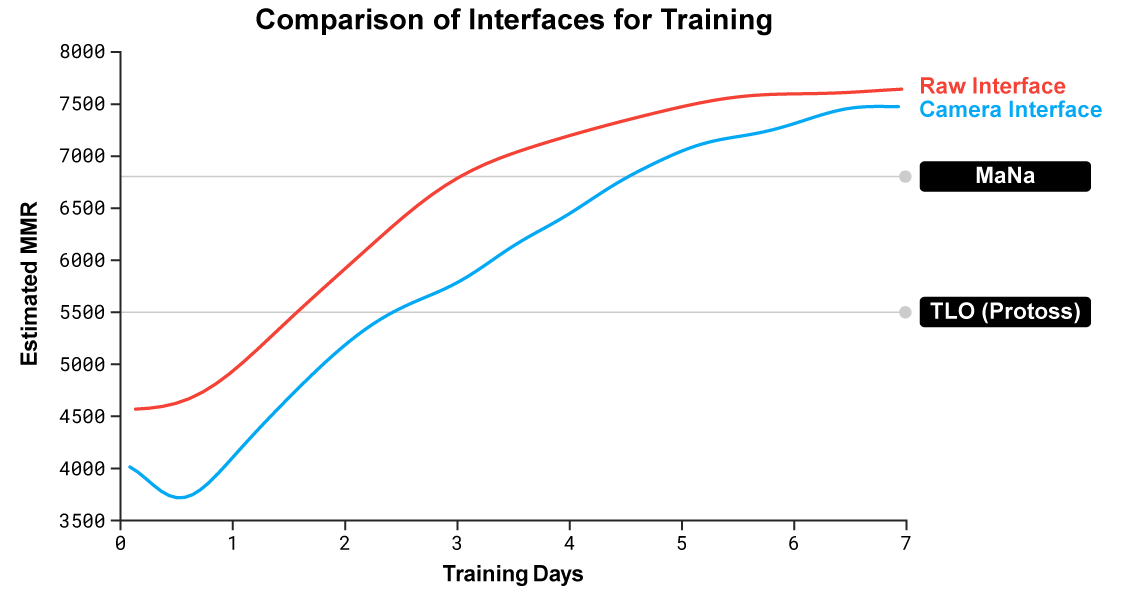
Raw 인터페이스와 카메라 인터페이스를 사용하는 AlphaStar의 성능. 새로 훈련된 카메라 에이전트가 raw 인터페이스를 사용하여 에이전트의 성능을 따르게 따라 잡을 수 있고 거의 동일하다는 것을 보여준다.
Raw 인터페이스를 사용하는 것과 AlphaStar 리그를 상대로 카메라 제어법을 배우는 두 가지 새로운 에이전트를 교육했습니다. 각 에이전트는 처음에 인간 데이터를 통한 supervised learning과 위에서 설명한 reinforcement learning을 통해 훈련되었습니다. 카메라 인터페이스를 사용하는 AlphaStar 버전은 내부 인터페이스에서 7000 MMR을 초과하는 raw 인터페이스와 거의 비슷했습니다. 전시회 경기에서, MaNa는 7일 동안 훈련된 카메라 인터페이스를 사용하는 프로토타입의 AlphaStar를 이겼습니다.
이 결과는 MaNa 및 TLO에 대한 AlphaStar의 성공이 우수한 클릭률, 빠른 반응 시간 또는 raw 인터페이스보다는 우수한 macro와 micro-strategic decision-making(역주. 컨트롤) 때문인 것으로 나타났습니다.
프로선수의 AlphaStar 평가
스타크래프트 게임을 통해 플레이어는 테란, 저그 또는 프로토스의 세 가지 종족 중 하나를 선택할 수 있습니다. 저희는 AlphaStar를 학습시키는 것에 교육시간과 편차를 줄이기 위해 현재 단 하나의 종족인 프로토스를 전문적으로 다루기로 결정했습니다. Note that, 동일한 교육을 모든 종족에 적용을 시킬 수 있습니다. 저희의 에이전트는 스타크래프트2(v4.6.2)에서 프로토스vs프로토스 게임을 진행하였고, CatalystLE라는 맵에서 진행되었습니다. AlphaStar의 성능을 평가하기 위해 저희는 TLO(저그가 주종족인 프로선수, 프로토스는 그랜드마스터의 실력)를 통해 테스트 하였고 AlphaStar는 다양한 빌드와 유닛으로 5-0으로 경기를 마무리했습니다. TLO는 “진짜 잘해서 놀랐어요. AlphaStar는 잘 알려진 전략과는 거리가 먼 플레이를 보여주었어요. 전혀 생각하지도 못한 전략으로 다가왔죠. 그 말은 곧 아직 우리가 경험하지 못한 새로운 방식의 전략들이 존재하다는 거겠죠” 라고 말했다.
AlphaStar:inside story
1주일간 에이전트를 교육 한 후, 저희는 세계에서 가장 강력한 스타크래프트2의 플레이어 중 하나인 MaNa 와 가장 강력한 10명의 프로토스 선수들과 대전했습니다. AlphaStar는 5경기에서 무패로 우승하여 강력한 전략 기술을 보여주었습니다. “AlphaStar의 놀라운 움직임과 매 경기 다른 전략으로 다가오는 것에 큰 감명을 받았다. 내가 전혀 생각하지 못했던 사람 같은 플레이를 보여주었다.” “나는 내 전략이 상대방의 실수를 유도하고 그의 인간적인(감정적인) 반응을 나에게 유리하도록 하는 것에 의존하고 있다는 사실을 깨달았다.”고 말했다.
AlphaStar, 그리고 다른 복잡한 문제들
스타크래프트는 그냥 게임이지만, 아주 복잡한 게임입니다. 저희는 AlphaStar를 뒷받힘 하는 기술들이 다른 문제 해결에 유용할 것이라 생각합니다. 예를 들면, 장시간 동안 많은 행동이 필요한 긴 sequence(때로는 수천, 수만의 움직임을 하는 1시간 경기 같은)같은 것들-완전하지 않은 정보들을 기반으로-에 도움이 될 수 있다고 생각합니다. 스타크래프트의 각 프레임은 입력의 한 단계로 사용되며, neural network는 매 프레임마다 나머지 게임에 대한 예상 동작 순서를 예측합니다. 매우 긴 데이터 sequence에 대해 복잡한 예측을 하는 근본적인 문제는 날씨 예측, 기후 모델링, 언어 이해 등과 같은 많은 실제 과제에서 나타납니다.
저희는 또한 우리의 훈련 방법 중 일부가 안전하고 견고한 인공지능 연구에 유용 할 수 있다고 생각합니다. AI에서 커다란 난제 중 하나는 시스템이 잘못 훈련 될 수 있는 가능성이 있으며 스타크래프트 프로 선수들은 이러한 실수를 유발할 창의적인 방법을 찾아 인공지능 시스템을 쉽게 이길 수 있음을 알았습니다. AlphaStar의 혁신적인 리그 기반 학습 과정은 가장 신뢰할 수 있고 잘못 될 가능성이 적은 접근 방식을 찾습니다. 저희는 AI 시스템의 안전성과 견고성을 향상시킬 수있는 이러한 접근법의 잠재력, 특히 에너지와 같이 안전성이 중요한 분야에서 복잡한 상황을 다루는 것이 필수적이라는 점을 기쁘게 생각합니다.
AlphaStar를 통해 만들어진 스타크래프트의 최고 수준의 플레이는 지금까지 만들어진 가장 복잡한 게임 중 하나를 돌파했다는 것을 의미합니다. 우리는 AlphaZero 및 AlphaFold와 같은 프로젝트와 함께 이러한 발전들은 언젠가는 세계에서 가장 중요하고 근본적인 과학적 문제에 대한 새로운 솔루션을 열어 줄 수 있는 지능형 시스템을 개발하려는 우리의 사명을 한 단계 진전시킨 것이라고 믿습니다.
Team Liquid의 TLO 및 MaNa에 대한 지원과 엄청난 기술에 감사드립니다. 우리는 블리자드와 스타크래프트 커뮤니티가 이 작업을 가능하게 하기 위해 지속적으로 지원해 주신 것에 대해서도 감사드립니다.
Download 11 replays here
Watch the exhibition game against MaNa
Watch a visualisation of AlphaStar’s entire second game against MaNa
AlphaStar Team:
Oriol Vinyals, Igor Babuschkin, Junyoung Chung, Michael Mathieu, Max Jaderberg, Wojtek Czarnecki, Andrew Dudzik, Aja Huang, Petko Georgiev, Richard Powell, Timo Ewalds, Dan Horgan, Manuel Kroiss, Ivo Danihelka, John Agapiou, Junhyuk Oh, Valentin Dalibard, David Choi, Laurent Sifre, Yury Sulsky, Sasha Vezhnevets, James Molloy, Trevor Cai, David Budden, Tom Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Toby Pohlen, Dani Yogatama, Julia Cohen, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Chris Apps, Koray Kavukcuoglu, Demis Hassabis, David Silver
With thanks to:
Ali Razavi, Daniel Toyama, David Balduzzi, Doug Fritz, Eser Aygün, Florian Strub, Guillaume Alain, Haoran Tang, Jaume Sanchez, Jonathan Fildes, Julian Schrittwieser, Justin Novosad, Karen Simonyan, Karol Kurach, Philippe Hamel, Ricardo Barreira, Scott Reed, Sergey Bartunov, Shibl Mourad, Steve Gaffney, Thomas Hubert, Yuhuai Wu, the team that created PySC2 and the whole DeepMind Team, with special thanks to the RPT, comms and events teams.